
日漫机翻经验谈(3)之BallonsTranslator
归档目录
BallonsTranslator 项目地址
资源搬运
通过网盘分享的文件:BallonsTranslator 链接: https://pan.baidu.com/s/1IDiIVm3yoYjB5ATC3DG7ng?pwd=h4em 提取码: h 4 em
安装建议
建议使用下面这种方法,全程国外网络环境。优点是操作简单,不会污染电脑的 Python 环境,卸载的时候也只需把文件夹删除即可。
之BallonsTranslator-1753724565009.png)
特别注意: 千万不要从 releases 下载!!!
之BallonsTranslator-1753939789102.png)
使用建议
Python 位置
Python 位置在后面的命令行模式会用到。在运行 launch_win.bat 或 launch_win_with_autoupdate.bat 后,终端窗口前几行会出现基本的环境与版本信息。其中有 Python 版本和 Python 路径,需要记下来。
Python version: 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
Python executable: D:\Tools\BallonsTranslator_dev_src_with_gitpython\ballontrans_pylibs_win\python.exe上面是我的 Python 版本和 Python 路径。
四个步骤及推荐配置
配置总览。
之BallonsTranslator-1753939864993.png)
基本上只需要把 LLM_API_Translator 的 endpoint, apikey 和 override model 换成你自己的配置就可以用。
有“文本检测”“OCR”“图像修复”“翻译”四个步骤,简要的介绍请参考日漫机翻经验谈 (1) 之总述.
推荐使用 ctd+mangaocr+lama_large_512 px+LLM_API_Translator.
具体推荐参数以及与其它选择的比较见下。
文本检测
总的来说,ysgyolo_S 150 best 比 ctd 能更好的过滤日漫中的拟声词。
ctd 检测结果如下。
之BallonsTranslator-1753785072791.png)
ysgyolo_S 150 best 检测结果如下。
之BallonsTranslator-1753785189089.png)
可以看到,ysgyolo_S 150 best 并没有检测第三格漫画左边表心理活动的文字区域。
但是 ysgyolo_S 150 best 在自动调节字体大小上有问题,容易过大或者过小,所以建议用 ctd 作为文本检测器。在某些情况下,我们可以通过调节参数来优化字体大小的自动调节,从而使用 ysgyolo_S 150 best, 详见后面的“使用技巧”篇
OCR
mangaocr 的介绍见日漫机翻经验谈 (2) 之 Saber-Translator.
mit 48 px, mit 48 px_ctc, mit 32 px 三者效果相差不大,更推荐 mit 48 px. mit 48 px 与 mangaocr 相比,前者在长文本上精度高很多,并且可以取色,但是速度较慢,而且振假名的处理不如后者。
在长文本上的识别精度对比。
之BallonsTranslator-1753788967897.png)
之BallonsTranslator-1753788999810.png)
取色,主要用于修图上,可以自动应用于字体颜色。mangaocr 由于不能取色,所以在黑底白字漫画上会出现黑底黑字的翻译效果,极为影响阅读体验。
之BallonsTranslator-1753789202349.png)
之BallonsTranslator-1753789330760.png)
然后是振假名的处理。
之BallonsTranslator-1753789816194.png)
之BallonsTranslator-1753789474836.png)
最后介绍一下 llm_ocr, 我至今还不知道为什么 gemini 2.5 flash 和 gemini 2.5 pro 用不了,但是可以用 gemini 2.0 flash 和 doubao 1.6 seed, 然而前者对汉字识别精度不高,而后者虽精度高但速度极慢,所以基本上用不到。
在此给出我的提示词。
You are a high-precision, AI-powered OCR engine specialized in manga and comics. Your task is to meticulously extract text by emulating a human reader's comprehension of the page layout and dialogue flow.\n\nFollow this multi-step process to achieve the highest accuracy:\n\n**Step 1: Initial Text Identification**\n- Scan the entire panel and identify all potential text elements. This includes dialogue in speech bubbles, narration boxes, and sound effects (SFX).\n- Tentatively classify each element.\n\n**Step 2: Detailed Text Block Analysis**\nFor each individual text block (a single speech bubble, narration box, or SFX), perform the following analysis in order:\n\n1. **Aggressive Furigana (ルビ) Filtering:** This is your first and most critical filtering step. You MUST be extremely vigilant in identifying and completely ignoring all furigana (the small phonetic characters, typically hiragana or katakana, found next to or above kanji). Under NO circumstances should any furigana character appear in the final output. Your focus is exclusively on the larger, primary characters.\n\n2. **Orientation and Transcription:** Based on the arrangement of the filtered primary characters, transcribe the text.\n * **Vertical Text (縦書き):** If characters are arranged vertically, transcribe them from **top-to-bottom**. If a block contains multiple vertical columns, read the columns from **right-to-left**.\n * **Horizontal Text (横書き):** If characters are arranged horizontally, transcribe them from **left-to-right**.\n\n3. **Punctuation Preservation:** All original Japanese punctuation marks MUST be retained and placed correctly in the transcribed text. This includes, but is not limited to: various brackets like `「` `」`, `『` `』`, `【` `】`, and parentheses `(` `)`; standard marks like `。` (period), `、` (comma), `!` (exclamation mark), and `?` (question mark); and other common symbols like `…` (ellipsis) and `~` (tilde).\n\n**Step 3: Semantic Grouping and Final Output Generation**\nThis is the most critical phase. You will now assemble the transcribed text blocks into a final, logical sequence based on their meaning and context.\n\n1. **Reading Order:** Process the text blocks according to the panel's natural reading flow (in Japanese manga, this is typically **right-to-left**, then **top-to-bottom**).\n\n2. **Speaker and Thought Cohesion:**\n * **COMBINE:** If a single, continuous thought or sentence from *one speaker* is split across multiple speech bubbles, you **MUST** merge the text from these bubbles into a single, coherent line in the output. A direct visual link (like a connecting tail) is a strong indicator for merging. However, even if bubbles are separate but clearly part of the same continuous statement from the same character, they should be combined.\n * **SEPARATE:** Text from different speakers, distinct and separate thoughts from the same speaker, or text from non-contiguous narration boxes must be placed on separate lines. Each new line should represent a new speaker or a definitive break in thought/narration.\n\n3. **Isolate Sound Effects (SFX):** Sound effects are always considered independent elements. Transcribe each SFX on its own dedicated line.\n\n**Final Output Rules:**\n- The output must be **pure text only**.\n- Do not include translations, summaries, annotations, or any commentary.\n- The language of the output must match the source language of the image.至于为什么写这么长,是因为不这么写的话,LLM 就不听话...
至于其他的 OCR 方式,除了团子翻译器以及 google 相关的两个 OCR 我没测试过外,效果都不太行。
图像修复
差别不大,选 lama_large_512 px.
翻译器
选 LLM_API_Translator, 然后正常填写即可。注意,我使用 Deepseek V 3 的时候会出现译文附带注解的情况,换了几套提示词都没用,但是有大佬给出了有效的提示词,参考日漫机翻经验谈 (2) 之 Saber-Translator.
endpoint 一栏填服务商的 baseurl, 注意 openai 格式的需以 v 1 结尾,比如硅基流动的 https://api.siliconflow.cn/v1/chat/completions, 应该填 https://api.siliconflow.cn/v1.
一些组合方式
其实主要是排除法,把不好用的先排除掉。
检测器首先排除 ysgyolo_S 150 best, 因为有字体大小问题,容易过大或者过小,所以(免费的)只能选 ctd.
然后是 OCR 模型,由于 Bug 反馈:ctd+mit48px 气泡框边缘文字未 OCR 这个 BUG 还未修复,所以只能选 mangaocr.
剩下的两个就是 LLM_API_Translator+lama_large_512 px 搭配了。
所以,个人的建议组合方式是 ctd+mangaocr+lama_large_512 px+LLM_API_Translator.
但是,如上文所述,mangaocr 存在一些问题,最明显的就是长文本 OCR 精度滑坡与无法取色,所以 ctd+mangaocr+lama_large_512 px+LLM_API_Translator 的组合方法也会存在这些问题。
批量模式
项目文档中的示例是
python launch.py --headless --exec_dirs "[DIR_1],[DIR_2]..."其实,准确来讲,这个 python 应该替换为上文要你记住的 Python 路径。
我的一个有效示例如下。
D:\Tools\BallonsTranslator_dev_src_with_gitpython\ballontrans_pylibs_win\python.exe launch.py --headless --exec_dirs "D:\目标文件夹\data,D:\目标文件夹\document,D:\目标文件夹\image,D:\目标文件夹\readme"其中,D:\Tools\BallonsTranslator_dev_src_with_gitpython\ballontrans_pylibs_win\python.exe 是我的 Python 路径。
使用技巧
手动标注
点击右下角的方框,按住右键后滑动会出现标注矩形框,如下图所示。
之BallonsTranslator-1753791801845.png)
之BallonsTranslator-1753791823329.png)
处理水印
之BallonsTranslator-1753720604149.png)
一种方法是,通过“替换原文关键词”将水印替换为空,然后开启过滤空的 OCR 结果。
另一种方法是对图片进行预处理,去除水印。
英文标点变中文标点
同上面的第一种方法,对标点符号进行替换。
多文件夹批量翻译
在 BallonsTranslator 的官方说明文档中提供了命令行模式的批量翻译选项。
python launch.py --headless --exec_dirs "[DIR_1],[DIR_2]..."可以看出这需要获取待翻译日文漫画的文件夹路径。
使用如下的 extract_filenames.bat 程序,批量获取父文件夹的父文件夹下的文件的绝对路径。
具体使用参考 https://github.com/WeMingT/extract-filenames.
@echo off
setlocal
:: 1. 设置代码页以支持中文文件名
:: 1. Set the code page to support Chinese filenames (UTF-8)
chcp 65001 > nul
:: 2. 定义相关路径
:: 2. Define relevant paths
set "parent_folder=%~dp0.."
set "output_file=%~dp0filenames_output.txt"
:: 3. 检查父文件夹是否存在
:: 3. Check if the parent folder exists
if not exist "%parent_folder%" (
echo.
echo [错误] 父文件夹不存在。
echo [ERROR] Parent folder does not exist.
echo.
echo - 请确保将此脚本放置在目标文件夹的子文件夹中。
echo - Please ensure this script is placed in a subfolder of the target directory.
goto end
)
:: 4. 使用 PowerShell 处理所有逻辑并直接生成输出文件
:: 4. Use PowerShell to handle all logic and generate the output file directly
powershell -NoProfile -ExecutionPolicy Bypass -Command ^
"$ParentPath = [System.IO.Path]::GetFullPath('%parent_folder%'); " ^
"if (-not (Test-Path -LiteralPath $ParentPath)) { exit 1; } " ^
"$Files = Get-ChildItem -LiteralPath $ParentPath -File | Sort-Object { [regex]::Replace($_.Name, '\d+', { $args[0].Value.PadLeft(20) }) }; " ^
"if ($Files.Count -eq 0) { exit 2; } " ^
"$FilenamesWithExt = ($Files | ForEach-Object { $_.Name }) -join ','; " ^
"$FilenamesNoExt = ($Files | ForEach-Object { $_.BaseName }) -join ','; " ^
"$AbspathWithExt = ($Files | ForEach-Object { $_.FullName }) -join ','; " ^
"$AbspathNoExt = ($Files | ForEach-Object { Join-Path $_.DirectoryName $_.BaseName }) -join ','; " ^
"$BallonsTranslatorCmd = \"D:\Tools\BallonsTranslator_dev_src_with_gitpython\ballontrans_pylibs_win\python.exe launch.py --headless --exec_dirs `\"$AbspathNoExt`\"\"; " ^
"$OutputContent = \"文件名:`r`n$($FilenamesWithExt)`r`n`r`n文件名(无后缀):`r`n$($FilenamesNoExt)`r`n`r`n绝对路径:`r`n$($AbspathWithExt)`r`n`r`n绝对路径(无后缀):`r`n$($AbspathNoExt)`r`n`r`nBallonsTranslator批处理路径:`r`n$($BallonsTranslatorCmd)\"; " ^
"[System.IO.File]::WriteAllText('%output_file%', $OutputContent, [System.Text.Encoding]::UTF8);"
:: 5. 检查 PowerShell 的退出代码以进行错误处理
:: 5. Check PowerShell's exit code for error handling
if %errorlevel% == 2 (
echo.
echo [提示] 父文件夹中没有找到任何文件。
echo [INFO] No files found in the parent folder.
goto end
)
if %errorlevel% == 1 (
echo.
echo [错误] PowerShell 无法解析父文件夹路径。
echo [ERROR] PowerShell could not resolve the parent folder path.
goto end
)
:: 6. 在屏幕上显示结果
:: 6. Display the results on the screen
echo.
echo -------------------- 结果 / Results --------------------
echo.
type "%output_file%"
echo.
echo ---------------------------------------------------------
echo.
echo 结果已保存到: %output_file%
echo Results have been saved to: %output_file%
:end
echo.
pause
exit /b多文件夹翻译结果批量打包
我们发现,日文漫画的翻译结果在 result 文件夹下,因此我们需要对 result 文件夹进行批量打包。这可以通过以下的 pack_results.bat 程序完成。
具体使用参考 https://github.com/WeMingT/pack-results.
@echo off
chcp 65001 >nul
echo.
echo ========================================
echo Result文件夹批量打包工具
echo ========================================
echo.
:: 检查是否安装了7-Zip
echo 正在检查7-Zip是否安装...
where 7z >nul 2>nul
if %errorlevel% neq 0 (
echo.
echo 错误:未找到7-Zip程序!
echo 请安装7-Zip或确保7z.exe在PATH环境变量中。
echo 下载地址:https://www.7-zip.org/
echo.
pause
exit /b 1
)
echo 7-Zip检查通过。
echo.
:: 获取当前目录
set "current_dir=%cd%"
echo 当前工作目录:%current_dir%
echo.
:: 创建输出目录
echo 正在准备输出目录...
set "output_dir=%current_dir%\zip_output"
if not exist "%output_dir%" (
mkdir "%output_dir%"
echo "已创建输出目录:%output_dir%"
) else (
echo "输出目录已存在:%output_dir%"
)
echo.
:: 创建日志文件
for /f "tokens=1-3 delims=/ " %%a in ("%date%") do set "mydate=%%a-%%b-%%c"
for /f "tokens=1-3 delims=:. " %%a in ("%time%") do set "mytime=%%a-%%b-%%c"
set "log_file=%output_dir%\pack_log_%mydate%_%mytime%.txt"
echo 准备写入日志文件...
echo 开始打包操作 - %date% %time% > "%log_file%" 2>nul
if exist "%log_file%" (
echo "工作目录: %current_dir%" >> "%log_file%"
echo "输出目录: %output_dir%" >> "%log_file%"
echo. >> "%log_file%"
echo "日志文件已创建:%log_file%"
) else (
echo 警告:无法创建日志文件。打包过程仍将继续,但不会记录日志。
)
echo.
echo ========================================
echo 开始处理文件夹
echo ========================================
echo.
:: 计数器
set /a total_folders_checked=0
set /a success_count=0
set /a error_count=0
set /a skipped_count=0
:: 创建临时文件列出所有文件夹
set "temp_list=%temp%\folder_list_%random%.txt"
dir /b /ad > "%temp_list%" 2>nul
:: 逐行读取文件夹列表
for /f "usebackq delims=" %%i in ("%temp_list%") do (
if /i not "%%i"=="zip_output" (
call :process_folder "%%i"
)
)
:: 清理临时文件
if exist "%temp_list%" del "%temp_list%"
goto :show_results
:process_folder
set "folder_name=%~1"
set /a total_folders_checked+=1
echo ----------------------------------------
echo 正在检查文件夹: "%folder_name%"
:: 检查是否存在result文件夹
if exist "%folder_name%\result" (
echo " -> 找到result文件夹,准备打包..."
:: 使用7z进行压缩,直接压缩result文件夹内的内容到zip文件根目录
pushd "%folder_name%\result" >nul 2>nul
if errorlevel 1 (
echo " -> [失败] 无法访问result子目录: %folder_name%\result"
set /a error_count+=1
if exist "%log_file%" echo [失败] %folder_name% - 无法访问result目录 - %date% %time% >> "%log_file%"
) else (
echo " -> 正在压缩: %output_dir%\%folder_name%.zip"
7z a -tzip "%output_dir%\%folder_name%.zip" * >nul 2>nul
if errorlevel 1 (
echo " -> [失败] 打包文件夹时出错: %folder_name%"
set /a error_count+=1
if exist "%log_file%" echo [失败] %folder_name% - 打包错误 - %date% %time% >> "%log_file%"
) else (
echo " -> [成功] 打包完成: %folder_name%.zip"
set /a success_count+=1
if exist "%log_file%" echo [成功] %folder_name% - %date% %time% >> "%log_file%"
)
popd >nul 2>nul
)
) else (
echo " -> [跳过] 未找到result文件夹在: %folder_name%"
set /a skipped_count+=1
if exist "%log_file%" echo [跳过] %folder_name% - 未找到result文件夹 - %date% %time% >> "%log_file%"
)
echo.
goto :eof
:show_results
echo ----------------------------------------
echo.
:: 显示统计结果
echo ========================================
echo 处理完成统计
echo ========================================
echo 总共检查文件夹数: %total_folders_checked%
echo 成功打包: %success_count%个
echo 失败: %error_count%个
echo 跳过: %skipped_count%个
echo.
echo "输出目录: %output_dir%"
if exist "%log_file%" echo "日志文件: %log_file%"
echo.
:: 写入日志文件总结
if exist "%log_file%" (
echo. >> "%log_file%"
echo ===== 打包完成统计 ===== >> "%log_file%"
echo 总共检查文件夹数: %total_folders_checked% >> "%log_file%"
echo 成功打包: %success_count%个 >> "%log_file%"
echo 失败: %error_count%个 >> "%log_file%"
echo 跳过: %skipped_count%个 >> "%log_file%"
echo 完成时间: %date% %time% >> "%log_file%"
)
::统计结果提示
if %total_folders_checked% equ 0 (
echo.
echo 注意:当前目录下没有找到任何子文件夹。
echo 请确保您在包含项目子文件夹的父目录中运行此脚本。
) else (
if %success_count% gtr 0 (
echo.
echo 处理完成!成功打包了 %success_count% 个文件夹的result内容。
) else (
echo.
echo 注意:已检查 %total_folders_checked% 个文件夹,但均未找到名为 result 的子文件夹。
echo 请确保:
echo 1. 您在正确的父目录中运行此脚本。
echo 2. 目标子文件夹中确实存在名为 result 的文件夹。
)
)
echo.
echo 按任意键退出...
pause >nulysgyolo_S 150 best 字体大小优化
首先需要声明,这种方法具有局限性,只适合同一部漫画的所有待翻译图片的字号差不多的情况。
可以从漫画中随机抽取 1/20 作为测试样本。
方法具体来说是调节 ysgyolo_S 150 best 的 font size multiplier, font size max 和 font size min 参数。
我一般设置为 font size multiplier = 1.6, font size max = 34 和 font size min = -1. 当然,这不具有通用性,需要根据具体的漫画图片来调节。
其原理是 font size multiplier 控制字号的放大倍数,font size min 控制最小字号,font size max 控制最大字号。
完整的工作流
我们在 待翻译漫画 目录下有以下需要翻译的日文漫画。

粘贴含 extract_filenames.bat 程序的文件夹到 待翻译漫画。
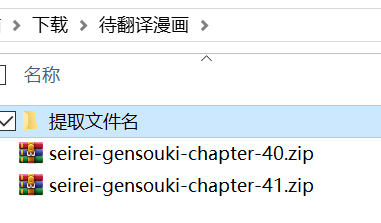
双击运行 extract_filenames.bat 程序。获得如下结果。
文件名:
seirei-gensouki-chapter-40.zip,seirei-gensouki-chapter-41.zip
文件名(无后缀):
seirei-gensouki-chapter-40,seirei-gensouki-chapter-41
绝对路径:
C:\Users\xxx\Downloads\待翻译漫画\seirei-gensouki-chapter-40.zip,C:\Users\xxx\Downloads\待翻译漫画\seirei-gensouki-chapter-41.zip
绝对路径(无后缀):
C:\Users\xxx\Downloads\待翻译漫画\seirei-gensouki-chapter-40,C:\Users\xxx\Downloads\待翻译漫画\seirei-gensouki-chapter-41解压待翻译的日文漫画压缩包,运行
D:\Tools\BallonsTranslator_dev_src_with_gitpython\ballontrans_pylibs_win\python.exe launch.py --headless --exec_dirs "C:\Users\xxx\Downloads\待翻译漫画\seirei-gensouki-chapter-40,C:\Users\xxx\Downloads\待翻译漫画\seirei-gensouki-chapter-41"其中,D:\Tools\BallonsTranslator_dev_src_with_gitpython\ballontrans_pylibs_win\python.exe 是我的 Python 路径。
翻译结束后,将 pack_results.bat 程序复制到 待翻译漫画 文件夹下,双击运行,即可得到翻译好的 zip 文件。
使用感受
BallonsTranslator 可能是我花时间最多的翻译器,但是效果并没有多少提升,原因也显而易见,因为它几乎把组合方式“限定死了”,其它的组合方式的探索差不多是无用功(当然也欢迎读者们留下更好的组合方式与参数配置)。
BallonsTranslator 较 Saber-Translator 的最大优势,个人认为是 ctd 检测器与大批量翻译,以及多样的模型选择。
BallonsTranslator 我现在已经不怎么用了,用得更多的是 manga-image-translator, 它解决了 BallonsTranslator 中 ctd+mangaocr+lama_large_512 px+LLM_API_Translator 组合的长文本 OCR 精度滑坡与无法取色的问题,并且在检测上更进一步,可以检测旋转的气泡。这是我后面将会介绍的。
部分参数说明
主要由询问 gemini 2.5 pro 得出,仅供参考。
ctd 参数说明
| 参数 (Parameter) | 示例值 (Value) | 解释 (Explanation) |
|---|---|---|
detect_size | 1280 | 检测尺寸。这是将输入图像调整到的尺寸,用于模型推理。模型会在这个分辨率的图像上进行文本检测。通常来说, - 值越大:能检测到更小的文本,精度可能更高,但处理速度更慢,显存/内存消耗也更大。 - 值越小:处理速度更快,资源消耗更低,但可能会漏掉图像中的微小文本。 |
det_rearrange_max_batches | 8 | 检测重排最大批次数。这是一个性能优化参数。在检测到多个文本区域后,系统可能会将这些区域裁剪下来进行批处理(例如,为了后续的识别或过滤)。此参数限制了在重排和批处理阶段一次可以处理的最大批次数量。调高此值可能在拥有强大 GPU 的情况下提升吞吐量,但会增加显存占用。 |
device | "cpu" | 运行设备。指定用于运行检测模型的硬件。 - "cpu":使用中央处理器。通用性好,无需特殊硬件,但速度较慢。- "cuda" 或 "gpu":使用 NVIDIA GPU 进行计算。速度远快于 CPU,是深度学习推理的首选,但需要正确安装 CUDA 环境和相应驱动。 |
font size multiplier | 1.0 | 字体大小乘数。一个调整因子,可能用于内部的字体大小估算或过滤逻辑。值为 1.0 表示不进行任何调整。如果将其设置为大于 1.0 的值,可能会在过滤时倾向于保留更大的文本;反之,小于 1.0 则可能倾向于保留更小的文本。这是一个微调参数,通常保持默认值即可。 |
font size max | -1 | 最大字体大小。用于过滤检测结果的参数。它设定了一个被检测文本的字体大小(通常以像素为单位)的上限。如果检测到的文本框估算出的字体大小超过这个值,该结果将被丢弃。这可以用来排除超大标题或非文本的图形元素。值为 -1 通常表示不设上限,即接受所有大小的文本。 |
font size min | -1 | 最小字体大小。与 font size max 对应,设定了被检测文本的字体大小的下限。小于该尺寸的文本将被过滤掉。这是一个非常有用的参数,可以有效去除图像中的噪点或非常微小、无意义的文本。值为 -1 通常表示不设下限,即不因字体过小而过滤任何结果。 |
mask dilate size | 2 | 掩码膨胀大小。这是一个图像后处理参数。模型检测文本时常会生成一个“掩码”(mask),即一个标示文本区域的二值图像。膨胀(Dilation)操作会“加粗”或扩大这个掩码的白色区域。此参数的作用是: - 将断裂的字符或单词连接起来,形成一个更完整的文本块。 - 使检测框能更完整地包裹住整个文本行。 值的大小(如 2)决定了膨胀的程度,值越大,膨胀效果越强。 |
ysgyolo 参数说明
| 参数 (Parameter) | 示例值 (Value) | 解释 (Explanation) |
|---|---|---|
model path | "data/models/ysgyolo_S150best.pt" | 模型文件路径。指向预训练好的模型权重文件。.pt 是 PyTorch 模型文件的常见扩展名。文件名 ysgyolo_S150best 可能表示这是 YOLO 架构的 S (Small) 尺寸模型,在第 150 个 epoch 训练时达到了最佳效果。 |
merge text lines | true | 合并文本行。一个布尔值(true 或 false)。如果设置为 true,算法会在检测到多个独立的文本行后,尝试将空间上邻近且排列合理的行合并成一个更大的文本块(text block)。这对于识别段落或完整的对话框非常有用。 |
confidence threshold | 0.3 | 置信度阈值。这是一个 0 到 1 之间的浮点数。模型对每个检测框都会给出一个置信度分数,表示“它有多确定这是一个文本框”。只有分数高于此阈值(如 0.3,即 30%)的检测结果才会被保留。提高此值可以减少误报(假阳性),但可能漏掉一些不清晰的文本;降低此值则相反。 |
IoU threshold | 0.5 | 交并比 (Intersection over Union) 阈值。用于“非极大值抑制”(NMS)过程。当多个检测框重叠并指向同一个文本目标时,NMS 会保留置信度最高的那个,并抑制掉其他与之重叠度(IoU)超过此阈值(如 0.5)的框。此参数用于消除冗余的检测结果,确保一个文本目标只被检测一次。 |
font size multiplier | 1.0 | 字体大小乘数。一个调整因子,用于内部的字体大小估算或过滤逻辑。值为 1.0 表示不进行调整。此参数可用于微调字体大小相关的后处理,一般保持默认值。 |
font size max | -1 | 最大字体大小。用于过滤检测结果。设定了一个被检测文本的估算字体大小的上限(单位通常是像素)。如果检测框内的字体估算大小超过此值,则该结果被丢弃。这可以用来排除巨大的标题或被误检为文本的图形。值为 -1 表示不设上限。 |
font size min | -1 | 最小字体大小。与 font size max 对应,设定了字体大小的下限。小于此尺寸的文本将被过滤掉,可以有效去除图像噪点或无意义的微小文字。值为 -1 表示不设下限。 |
detect size | 1024 | 检测尺寸。将输入图像调整到此尺寸(如 1024 x 1024)后送入模型进行推理。值越大,对小文本的检测能力越强,但速度越慢、资源消耗越大。值越小,速度越快,但可能遗漏小文本。 |
device | "cpu" | 运行设备。指定用于模型推理的硬件。 - "cpu":使用中央处理器,通用但速度慢。- "cuda" 或 "gpu":使用 NVIDIA GPU,需要相应的硬件和 CUDA 环境,速度快得多。 |
label | {"vertical_textline": true, ...} | 标签过滤器。这是一个非常关键的参数,它定义了你希望从模型输出中保留哪些类型的文本。模型可以检测多种方向的文本,你可以通过设置 true 或 false 来选择性地保留它们:- vertical_textline: 垂直文本行。- horizontal_textline: 水平文本行。- angled_vertical_textline: 有角度的垂直文本行。- angled_horizontal_textline: 有角度的水平文本行。- textblock: 文本块(可能是由多个文本行合并而成)。 |
source text is vertical | true | 源文本为垂直方向。这是一个给后处理算法的提示。当设置为 true 时,它告诉算法,图像中的主要文本流是垂直的(例如日本漫画)。这个信息可以帮助 merge text lines 功能更准确地将垂直排列的文本行合并成文本块。 |
mask dilate size | 2 | 掩码膨胀大小。一个图像后处理参数。模型可能会为每个文本生成一个像素级的掩码。膨胀(Dilation)操作会扩大这个掩码的范围。此参数可以帮助将断开的字符连接起来,或使最终生成的边界框更完整地包裹住文本,避免边缘字符被截断。值越大,膨胀效果越强。 |
llm_ocr 参数说明
| 参数 (Parameter) | 示例值 (Value) | 解释 (Explanation) |
|---|---|---|
provider | "OpenAI" | 服务提供商。指定所使用的 LLM 服务的提供商或 API 兼容类型。设置为 "OpenAI" 通常意味着该系统使用与 OpenAI API 格式兼容的接口。 |
api_key | "[REDACTED]" | API 密钥。用于向 LLM 服务提供商进行身份验证的凭证。这是一个必须替换的敏感信息,请填入你自己的有效 API 密钥。 |
endpoint | "[PROVIDER_ENDPOINT]" | API 端点。API 请求被发送到的具体服务器 URL。你需要将其设置为你所使用的 LLM 服务提供商提供的实际端点地址。 |
model | "" (空字符串) | 模型名称。用于指定要使用的 LLM 模型。在此配置中,该字段为空,实际使用的模型由 override_model 参数决定。 |
override_model | "[MODEL_NAME]" | 覆盖模型名称。此参数会覆盖 model 字段的设置,强制使用指定的模型。请在此处填入你希望使用的具体模型名称(例如 gpt-4-vision-preview 等)。 |
language | "Auto Detect" | 语言。指定图像中文本的语言。设置为 "Auto Detect" 表示让 LLM 自动检测和识别语言。如果提前知道图像的语言(如 "Japanese"、"Chinese"、"English"),明确指定可以提高识别的准确性。 |
prompt | "Recognize the text in this image." | 用户提示。这是每次 API 请求时,随图像一起发送给 LLM 的直接指令。它告诉 LLM 当前任务的核心目标:识别图像中的文本。这通常是比较通用的、即时的指令。 |
system_prompt | (长文本) | 系统提示/角色设定。这是一个非常关键的“元指令”,在对话开始前提供给 LLM,用于设定其角色、行为准则和详细的任务指令。这个详细的提示将 LLM 塑造成一个专业的漫画 OCR 引擎,并给出了极其具体的规则: 1. 角色定义: “你是一个高精度的、专攻漫画的 AI OCR 引擎”。 2. 核心规则: 严格过滤注音假名(Furigana)、正确处理竖排和横排文本、保留所有原始标点符号。 3. 高级逻辑: 遵循漫画阅读顺序(从右到左,从上到下)、将同一角色的连续对话合并为一行、将不同角色或音效(SFX)的文本分行处理。 4. 输出格式: 最终只输出纯文本。 这个系统提示是实现高质量、结构化漫画 OCR 的关键。 |
proxy | "" (空字符串) | 代理服务器。用于网络请求的代理服务器地址。如果留空,则直接连接 API 端点。如果填写了代理地址(如 http://127.0.0.1:7890),所有 API 请求都会通过该代理发送。这在需要绕过网络限制或防火墙时非常有用。 |
delay | 1.0 | 请求延迟。这是一个速率控制参数,单位是秒。它定义了在两次连续 API 请求之间必须等待的最小时间。设置为 1.0 意味着程序在每次请求后会至少等待 1 秒再发起下一次请求,以避免过于频繁地调用 API。 |
requests_per_minute | 15 | 每分钟请求数。另一个速率控制参数,用于限制每分钟内可以发出的最大 API 请求数量。设置为 15 表示在一分钟的窗口内,最多只能调用 15 次 API。这通常是为了遵守服务提供商的用量限制(Rate Limit Policy),防止因请求过于频繁而被临时封禁。 |
mit 48 px 参数说明
| 参数 (Parameter) | 示例值 (Value) | 解释 (Explanation) |
|---|---|---|
chunk_size | 16 | 批处理大小 (Batch Size)。它定义了一次性送入 OCR 模型进行批量识别的文本行图像数量。系统会将检测到的多个文本行(已经裁剪为独立的图像)分组,每组最多包含 16 张图像,然后将这一整组(批次)送入模型进行并行处理。 - 调高此值:在拥有强大 GPU 的情况下,可以显著提升识别的总吞吐量(每秒识别的行数),但会占用更多显存(VRAM)。 - 调低此值:可以减少内存/显存的消耗,适用于硬件资源有限的设备。 |
device | "cpu" | 运行设备。指定用于运行 OCR 模型的硬件。 - "cpu":使用中央处理器。通用性好,无需特殊硬件,但识别速度相对较慢。- "cuda" 或 "gpu":使用 NVIDIA GPU 进行计算。速度远快于 CPU,是进行批量 OCR 识别的首选,但需要有支持 CUDA 的 NVIDIA 显卡并正确配置环境。 |
lama_large_512 px 参数说明
| 参数 (Parameter) | 示例值 (Value) | 解释 (Explanation) |
|---|---|---|
inpaint_size | 1536 | 修复尺寸。这是在执行图像修复任务前,将输入图像调整到的处理尺寸。模型会在此分辨率的图像上进行计算。 - 为什么要设置这个值? 尽管模型是在 512 px 的数据上训练的,但将待处理图像放大到一个更高的分辨率(如 1536px)再进行修复,可以生成更精细、更高质量的结果,有效避免修复区域出现模糊或像素化。 - 影响:值越大,修复效果越精细,但处理速度越慢,消耗的内存/显存也越多。反之,值越小则速度越快,但可能牺牲细节。 |
device | "cpu" | 运行设备。指定用于运行修复模型的硬件。 - "cpu":使用中央处理器。通用性好,但对于图像修复这类计算密集型任务来说,速度会非常慢。- "cuda" 或 "gpu":使用 NVIDIA GPU 进行计算。速度远超 CPU,是进行图像修复任务的强烈推荐选项。需要正确安装 CUDA 环境和驱动。 |
precision | "fp32" | 计算精度 (Computational Precision)。此参数定义了模型在计算时使用的浮点数精度。 - "fp32" (单精度):使用 32 位浮点数。这是标准的、最精确的模式,提供最高的数值稳定性,但内存占用和计算量也最大。- "fp16" (半精度):使用 16 位浮点数。在兼容的 GPU 上(如 NVIDIA RTX 系列),可以显著提升速度并减少约一半的显存占用,但可能会有微小的精度损失(对于图像修复任务通常可忽略不计)。这是一个在性能和资源消耗之间进行权衡的优化选项。 |
LLM_API_Translator 参数说明
| 参数 (Parameter) | 示例值 (Value) | 解释 (Explanation) |
|---|---|---|
provider | "OpenAI" | 服务提供商。指定使用的 API 遵循的格式标准。"OpenAI" 表示该系统将以 OpenAI API 的格式来构建和发送请求,即使 endpoint 指向的是一个本地或第三方服务。 |
apikey | "[REDACTED_API_KEY]" | API 密钥。用于向 LLM 服务提供商进行身份验证的凭证。这是一个必须替换的敏感信息,你需要填入自己的有效 API 密钥。 |
multiple_keys | "" (空字符串) | 多密钥列表。一个可选字段,可以填入用逗号分隔的多个 API 密钥。如果提供,系统可以轮换使用这些密钥,有助于分摊请求负载或绕过单一密钥的速率限制。 |
model | "OAI: gpt-3.5-turbo" | 模型名称。指定默认使用的 LLM 模型。OAI: 前缀可能是此应用程序内部用于标识官方 OpenAI 模型的约定。此设置可以被 override model 参数覆盖。 |
override model | "[CUSTOM_MODEL_NAME]" | 覆盖模型名称。此参数会强制使用指定的模型,覆盖 model 字段的设置。这对于使用本地托管的模型(如通过 LM Studio、Jan 等工具)或第三方供应商提供的特定模型非常有用。 |
endpoint | "[API_ENDPOINT_URL]" | API 端点。API 请求被发送到的具体服务器 URL。它可以是官方的 OpenAI 地址,也可以是第三方服务商的地址,或者是本地服务器的地址(如 http://localhost:3000/v1)。 |
prompt template | "Please help me to... {to_lang}..." | 提示模板(非聊天模式)。这是一个用于构建发送给非聊天模型的指令的模板。{to_lang} 是一个占位符,程序运行时会自动替换为目标语言(如 "Simplified Chinese")。 |
chat system template | "You are a professional... {to_lang}." | 聊天系统提示模板。这是为聊天模型(如 GPT-3.5/4)设计的系统提示或角色设定。它在对话开始前告诉模型其扮演的角色(专业翻译引擎)、翻译风格(口语化、优雅流畅)和行为准则(只翻译不解释,保留原文格式等)。这是实现高质量翻译的关键部分。 |
chat sample | (日-中翻译示例) | 聊天示例(Few-shot Prompting)。这是一个提供给模型的“小样本”示例,向其展示了期望的输入(source)和输出(target)格式及质量。通过这种方式,可以引导模型更好地遵循指令,生成格式正确、风格符合要求的翻译结果。 |
invalid repeat count | 2 | 无效重复计数。一个质量控制参数。如果模型连续 2 次返回无效或类似乱码的结果,系统可能会停止重试或采取其他纠错措施。 |
max requests per minute | 60 | 每分钟最大请求数。一个速率控制参数,限制每分钟最多能向 API 发送 60 次请求。这用于遵守服务提供商的速率限制策略,防止账户因请求过于频繁而被暂时禁用。 |
delay | 0.3 | 请求延迟。两次连续 API 请求之间的最小等待时间(秒)。设置为 0.3 秒,与 max requests per minute 共同作用,平滑请求速率。 |
max tokens | 8192 | 最大令牌数。限制 LLM 在一次响应中生成的最大令牌(token,可看作单词或字符片段)数量。这有助于控制成本和防止模型生成过长的无用输出。 |
temperature | 0.5 | 温度。控制输出的随机性。值越低(如 0.2),输出越确定、越保守;值越高(如 0.8),输出越具创造性和多样性。0.5 是一个相对平衡的值,既能保证翻译的准确性,又带有一点自然的流畅度。 |
top p | 1.0 | Top-p (核心采样)。另一种控制随机性的方法。值为 1.0 表示不启用 Top-p 采样。如果设置为较低的值(如 0.9),模型会从一个累积概率为 90% 的小范围词汇中选择下一个词,从而降低生成罕见词的概率。通常只调整 temperature 或 top p 中的一个。 |
retry attempts | 12 | 重试次数。当 API 请求失败时(例如网络问题或服务器错误),系统将尝试重新发送请求的最大次数。 |
retry timeout | 10 | 重试超时。每次重试前等待的秒数。 |
proxy | "" (空字符串) | 代理服务器。用于网络请求的代理服务器地址。如果留空,则直接连接 API 端点。若填写,则所有 API 请求将通过此代理发送,可用于绕过网络限制。 |
frequency penalty | 0.0 | 频率惩罚。一个 -2.0 到 2.0 之间的数字。正值会降低模型重复相同单词的概率。0.0 表示不施加惩罚,这对于翻译任务通常是合适的。 |
presence penalty | 0.0 | 存在惩罚。一个 -2.0 到 2.0 之间的数字。正值会鼓励模型引入新概念,而不是重复已经提到的内容。0.0 表示不施加惩罚。 |
low vram mode | false | 低显存模式。一个布尔值,可能用于本地运行模型时。当设置为 true 时,系统可能会采取措施减少显存(VRAM)占用,例如减小批处理大小或使用精度更低的模型加载方式。对于纯 API 调用,此参数可能无效。 |
可以参考的其他教程
关注的比较少,欢迎补充!